
8:30 p.m.
All,
Sorry for the long silence on the mailing list. However, we have made some substantial
progress recently as we prepare for our ISC BOF next week. For those of you at ISC,
please join us from 11 to 12 on Tuesday<x-apple-data-detectors://0> in Substanz
1&2.
The progress that we have made recently happened because a bunch of us were attending a
German workshop last month at Dagstuhl and had multiple discussions about the benchmark.
Here’s the highlights from what was discussed and the progress that we made at Dagstuhl:
1. General agreement that the IOR-hard, IOR-easy, mdtest-hard, mdtest-easy approach is
appropriate.
2. We should add a ‘find’ command as this is a popular and important workload.
3. The multiple bandwidth measurements should be combined via geometric mean into one
bandwidth.
4. The multiple IOPs measurements should also be combined via geometric mean into one
IOPs.
5. The bandwidth and the IOPs should be multiplied to create one final score.
6. The ranking uses that final score but the webpage can be sorted using other
metrics.
7. The webpage should allow filtering as well so, for example, people can look at only
the HDD results.
8. We should separate the write/create phases from the read/stat phases to help ensure
that caching is avoided
9. Nathan Hjelm volunteered to combine the mdtest and IOR benchmarks into one git repo
and has now done so. This removes the #ifdef mess from mdtest and now they both share the
nice modular IOR backend
So the top-level summary of the benchmark in pseudo-code has become:
# write/create phase
bw1 = ior_easy -write [user supplies their own parameters maximizing data writes that can
be done in 5 minutes]
md1 = md_test_easy -create [user supplies their own parameters maximizing file creates
that can be done in 5 minutes]
bw2 = ior_hard -write [we supply parameters: unaligned strided into single shared file]
md2 = md_test_hard -create [we supply parameters: creates of 3900 byte files into single
shared directory]
# read/stat phase
bw3 = ior_easy -read [cross-node read of everything that was written in bw1]
md3 = md_test_easy -stat [cross-node stat of everything that was created in md1]
bw4 = ior_hard -read
md4 = md_test_hard -stat
# find phase
md5 = [we supply parameters to find a subset of the files that were created in the
tests]
# score phase
bw = geo_mean( bw1 bw2 bw3 bw4)
md = geo_mean( md1 md2 md3 md4 bd5)
total = bw * md
Now we are moving on to precisely define what the parameters should look like for the hard
tests and to create a standard so that people can start running it on their systems. By
doing so, we will define the formal process so we can actually make this an official
benchmark. Please see the attached file in which we’ve started precisely defining these
parameters. Let’s start iterating please on this file to get these parameters correct.
Thanks,
John

7:01 p.m.
Hi all,
IOR has an option to allocate a certain amount of the hosts memory. I suggest that we set
this to 90-95 percent and the total amount of data written as twice the size of the main
memory? Otherwise, the 10+ PB main memory of SUMMIT would make the list useless ;)
If I read everything correctly the current run rules define an execution time of 5 minutes
and just count the numbers of bytes/iops/files touched during this time. I agree that most
of the time our users do I/O in bursts. Is the benchmark basically only about “who can
write the most data with one file per process in 5 mins”? Why 5 minutes and not “how long
does it take to dump 80% of the main memory to some redundant permanent storage” (with
fsync())?
Do we want to define some rules about how safe the data has to be? Should it be OK if this
data ends up in a single burst buffer and there is no copy somewhere? I would recommend
that the results are only valid if data survives one failure of one of the storage devices
used.
For example: For the mdtest-workload I could imagine a file system that has directory
locking turned off and is using an SSD/NVRAM backend and thus would just behave like the
“IOR hard” workload.
Another point is that I am more a fan of application driven benchmarks. The numbers above
do not tell me anything about my applications, so why should I actually run the benchmark?
Just to to be “on the list”?
Application driven benchmarks (something like SPEC CPU, but SPEC I/O), that scale with the
machine (and with the machines main memory) could actually become a standard that also the
industry could use to advertise their systems.
In addition, if we as a site have I/O patterns that are close to one of the benchmarks, we
could put some weight on this benchmark and adjust our tenders and the industry partner
would know how to design the storage system with respect to our special requirements. Just
because they know the I/O pattern because it is a standard and they know how to deal with
it.
One more thing that the current approach does not deal with at all is the fact that in
very near future applications will access permanent storage using interfaces that IOR does
not cover and store data by using mov() instructions in the CPU. Thus, if the list is
established using some combination of IOR+MDTEST+POSIX, I think it has no chance to
reflect the really fast I/O subsystems that are coming like <http://pmem.io/>
http://pmem.io/
Sorry for the lengthy statement …
Regards, Michael
--
Dr.-Ing. Michael Kluge
Technische Universität Dresden
Center for Information Services and
High Performance Computing (ZIH)
D-01062 Dresden
Germany
Contact:
Falkenbrunnen, Room 240
Phone: (+49) 351 463-34217
Fax: (+49) 351 463-37773
e-mail: <mailto:michael.kluge@tu-dresden.de> michael.kluge(a)tu-dresden.de
WWW: <http://www.tu-dresden.de/zih> http://www.tu-dresden.de/zih
Von: IO-500 [mailto:io-500-bounces@vi4io.org] Im Auftrag von John Bent
Gesendet: Freitag, 16. Juni 2017 22:30
An: io-500(a)vi4io.org
Betreff: [IO-500] Detailed benchmark proposal
All,
Sorry for the long silence on the mailing list. However, we have made some substantial
progress recently as we prepare for our ISC BOF next week. For those of you at ISC,
please join us from 11 to 12 on Tuesday <x-apple-data-detectors://0> in Substanz
1&2.
The progress that we have made recently happened because a bunch of us were attending a
German workshop last month at Dagstuhl and had multiple discussions about the benchmark.
Here’s the highlights from what was discussed and the progress that we made at Dagstuhl:
1. General agreement that the IOR-hard, IOR-easy, mdtest-hard, mdtest-easy approach is
appropriate.
2. We should add a ‘find’ command as this is a popular and important workload.
3. The multiple bandwidth measurements should be combined via geometric mean into one
bandwidth.
4. The multiple IOPs measurements should also be combined via geometric mean into one
IOPs.
5. The bandwidth and the IOPs should be multiplied to create one final score.
6. The ranking uses that final score but the webpage can be sorted using other metrics.
7. The webpage should allow filtering as well so, for example, people can look at only the
HDD results.
8. We should separate the write/create phases from the read/stat phases to help ensure
that caching is avoided
9. Nathan Hjelm volunteered to combine the mdtest and IOR benchmarks into one git repo and
has now done so. This removes the #ifdef mess from mdtest and now they both share the
nice modular IOR backend
So the top-level summary of the benchmark in pseudo-code has become:
# write/create phase
bw1 = ior_easy -write [user supplies their own parameters maximizing data writes that can
be done in 5 minutes]
md1 = md_test_easy -create [user supplies their own parameters maximizing file creates
that can be done in 5 minutes]
bw2 = ior_hard -write [we supply parameters: unaligned strided into single shared file]
md2 = md_test_hard -create [we supply parameters: creates of 3900 byte files into single
shared directory]
# read/stat phase
bw3 = ior_easy -read [cross-node read of everything that was written in bw1]
md3 = md_test_easy -stat [cross-node stat of everything that was created in md1]
bw4 = ior_hard -read
md4 = md_test_hard -stat
# find phase
md5 = [we supply parameters to find a subset of the files that were created in the tests]
# score phase
bw = geo_mean( bw1 bw2 bw3 bw4)
md = geo_mean( md1 md2 md3 md4 bd5)
total = bw * md
Now we are moving on to precisely define what the parameters should look like for the hard
tests and to create a standard so that people can start running it on their systems. By
doing so, we will define the formal process so we can actually make this an official
benchmark. Please see the attached file in which we’ve started precisely defining these
parameters. Let’s start iterating please on this file to get these parameters correct.
Thanks,
John

7:57 p.m.
Dear Michael,
thanks for the comments.
Do we want to define some rules about how safe the data has to be?
Should it
be OK if this data ends up in a single burst buffer and there is no copy
somewhere? I would recommend that the results are only valid if data
survives one failure of one of the storage devices used.
It is valid to run the benchmark only on Burst Buffer (potentially
less resilient), or on a persistent file system.
It must be absolutely reported how the benchmark was run (and where).
For example: For the mdtest-workload I could imagine a file system
that has
directory locking turned off and is using an SSD/NVRAM backend and thus
would just behave like the “IOR hard” workload.
Yes, that indeed could be the case for mdtest for which caching may
kick in, therefore, we are also looking into a workload driven test
that can exceed any cache (or must be guaranteed to exceed).
Another point is that I am more a fan of application driven
benchmarks. The
numbers above do not tell me anything about my applications, so why should I
actually run the benchmark? Just to to be “on the list”?
Agreed, many like application benchmarks.
The goal is that easy reflects optimized application workloads and
hard unoptimized (random) workloads.
IOR shall be for data driven and the metadata benchmark for metadata
and small object driven (e.g., many concurrent compilations of files).
In that sense, it is useful to be on the list, to run the benchmark
and understand what is going on.
Note that all numbers must be reported and will be listed, one could
sort the list based on metadata (hard) results.
In addition, if we as a site have I/O patterns that are close to one
of the
benchmarks, we could put some weight on this benchmark and adjust our
tenders and the industry partner would know how to design the storage system
with respect to our special requirements. Just because they know the I/O
pattern because it is a standard and they know how to deal with it.
Yes that is the idea.
The site offers many characteristics including metadata.
One more thing that the current approach does not deal with at all is
the
fact that in very near future applications will access permanent storage
using interfaces that IOR does not cover and store data by using mov()
instructions in the CPU. Thus, if the list is established using some
combination of IOR+MDTEST+POSIX, I think it has no chance to reflect the
really fast I/O subsystems that are coming like http://pmem.io/
Yes, we have to take care of this, likewise for object interfaces and S3.
This is already partly implemented in the md-real-io benchmark that
supports many backends.
Backends that could be used for the other benchmarks, too.
IOR has an option to allocate a certain amount of the hosts memory.
I
suggest that we set this to 90-95 percent and the total amount of data
written as twice the size of the main memory? Otherwise, the 10+ PB main
memory of SUMMIT would make the list useless ;)
One may use it. Goal is that the workload must exceed memory cache on
the client.
If one has to use it to ensure it because the main memory is used as
cache, then please do so.
Otherwise there is (not yet) an obligation.
The intent of the workload will be documented though and serves as
driver for running a benchmark.
If I read everything correctly the current run rules define an
execution
time of 5 minutes and just count the numbers of bytes/iops/files touched
during this time. I agree that most of the time our users do I/O in bursts.
Is the benchmark basically only about “who can write the most data with one
file per process in 5 mins”? Why 5 minutes and not “how long does it take to
dump 80% of the main memory to some redundant permanent storage” (with
fsync())?
5 minutes have been chosen (arbitrarily) within the community, 4
benchmark runs + find, typically 25 minutes, could be a bit longer.
Are you comming to the BoF during ISC?
Some of the things had been disussed, problem is the irregular progress.
My goal during ISC is that we will optimize the organization of this
and we (all) make a proper plan for the future for the IO500.
So thanks again,
Julian
8:50 a.m.
On Jun 18, 2017, at 9:57 PM, Julian Kunkel
<juliankunkel@googlemail.com<mailto:juliankunkel@googlemail.com>> wrote:
Some of the things had been disussed, problem is the irregular progress.
My goal during ISC is that we will optimize the organization of this
and we (all) make a proper plan for the future for the IO500.
I think we have had great recent progress and I optimistically sense that our group, and
the wider community, is coming to consensus around the script that George has been working
on. Therefore, I think a very realistic goal for us is to emerge from our BoF with a
completely defined benchmark and then start asking people to submit results.
It would be super useful however if someone else in the community can have a chance to run
George’s script (make some modifications as needed for your local environment) and report
back how it went.
Thanks,
John

5:10 a.m.
On Jun 18, 2017, at 1:01 PM, Michael Kluge <michael.kluge(a)tu-dresden.de> wrote:
IOR has an option to allocate a certain amount of the hosts memory. I suggest that we set
this to 90-95 percent and the total amount of data written as twice the size of the main
memory? Otherwise, the 10+ PB main memory of SUMMIT would make the list useless ;)
If I read everything correctly the current run rules define an execution time of 5
minutes and just count the numbers of bytes/iops/files touched during this time. I agree
that most of the time our users do I/O in bursts. Is the benchmark basically only about
“who can write the most data with one file per process in 5 mins”? Why 5 minutes and not
“how long does it take to dump 80% of the main memory to some redundant permanent storage”
(with fsync())?
The reason that a fixed time of 5 minutes was chosen for the write time is that this is
typically the maximum time to dump a full-system checkpoint every hour to get 90% compute
efficiency. If the limit is based on a particular data size then as you say the writes
might fit entirely into RAM and the storage isn't exercised at all. Conversely, for
checkpoints the size is rarely larger than the total RAM size.
Do we want to define some rules about how safe the data has to be?
Should it be OK if this data ends up in a single burst buffer and there is no copy
somewhere? I would recommend that the results are only valid if data survives one failure
of one of the storage devices used. For example: For the mdtest-workload I could imagine
a file system that has directory locking turned off and is using an SSD/NVRAM backend and
thus would just behave like the “IOR hard” workload.
The goal of the benchmark is that there is a separate measurement for each layer of the
storage system. That would give one result for a flash/burst buffer tier, a separate
result for the disk-based storage.
Another point is that I am more a fan of application driven
benchmarks. The numbers above do not tell me anything about my applications, so why should
I actually run the benchmark? Just to to be “on the list”?
Applications are going to be different, even among HPC sites. The goal of the benchmark
is to try and determine the outer limits of the performance space of the storage. How
does it handle large aligned reads/writes, how does it handle unaligned small IOPS? How
fast are the primitive metadata operations and small files? With this raw information, it
should (in theory) be possible to derive the IO behaviour of actual applications.
Application driven benchmarks (something like SPEC CPU, but SPEC
I/O), that scale with the machine (and with the machines main memory) could actually
become a standard that also the industry could use to advertise their systems.
This benchmark is also intended to scale with the system size and performance, rather than
being a fixed size. At the same time, they are intended to be run within a reasonable
time period rather than taking many hours to run.
In addition, if we as a site have I/O patterns that are close to one
of the benchmarks, we could put some weight on this benchmark and adjust our tenders and
the industry partner would know how to design the storage system with respect to our
special requirements. Just because they know the I/O pattern because it is a standard and
they know how to deal with it.
Since the benchmark itself is essentially capturing orthogonal performance parameters of
the storage system, it should be possible to weight the results of the different test
phases to get something approaching your desired performance characteristics.
One more thing that the current approach does not deal with at all is
the fact that in very near future applications will access permanent storage using
interfaces that IOR does not cover and store data by using mov() instructions in the CPU.
Thus, if the list is established using some combination of IOR+MDTEST+POSIX, I think it
has no chance to reflect the really fast I/O subsystems that are coming like
http://pmem.io/
The benchmark is not necessarily tied to POSIX. With IOR it is possible to run different
backend IO interfaces (HDF5, MPI-IO, S3 in newer versions), and I believe that mdtest has
been updated to do the same. It should be possible to interface IOR/mdtest with
persistent memory storage systems like DAOS as well.
Cheers, Andreas
Von: IO-500 [mailto:io-500-bounces@vi4io.org] Im Auftrag von John
Bent
Gesendet: Freitag, 16. Juni 2017 22:30
An: io-500(a)vi4io.org
Betreff: [IO-500] Detailed benchmark proposal
All,
Sorry for the long silence on the mailing list. However, we have made some substantial
progress recently as we prepare for our ISC BOF next week. For those of you at ISC,
please join us from 11 to 12 on Tuesday in Substanz 1&2.
The progress that we have made recently happened because a bunch of us were attending a
German workshop last month at Dagstuhl and had multiple discussions about the benchmark.
Here’s the highlights from what was discussed and the progress that we made at Dagstuhl:
• General agreement that the IOR-hard, IOR-easy, mdtest-hard, mdtest-easy approach is
appropriate.
• We should add a ‘find’ command as this is a popular and important workload.
• The multiple bandwidth measurements should be combined via geometric mean into one
bandwidth.
• The multiple IOPs measurements should also be combined via geometric mean into one
IOPs.
• The bandwidth and the IOPs should be multiplied to create one final score.
• The ranking uses that final score but the webpage can be sorted using other metrics.
• The webpage should allow filtering as well so, for example, people can look at only
the HDD results.
• We should separate the write/create phases from the read/stat phases to help ensure
that caching is avoided
• Nathan Hjelm volunteered to combine the mdtest and IOR benchmarks into one git repo
and has now done so. This removes the #ifdef mess from mdtest and now they both share the
nice modular IOR backend
So the top-level summary of the benchmark in pseudo-code has become:
# write/create phase
bw1 = ior_easy -write [user supplies their own parameters maximizing data writes that can
be done in 5 minutes]
md1 = md_test_easy -create [user supplies their own parameters maximizing file creates
that can be done in 5 minutes]
bw2 = ior_hard -write [we supply parameters: unaligned strided into single shared file]
md2 = md_test_hard -create [we supply parameters: creates of 3900 byte files into single
shared directory]
# read/stat phase
bw3 = ior_easy -read [cross-node read of everything that was written in bw1]
md3 = md_test_easy -stat [cross-node stat of everything that was created in md1]
bw4 = ior_hard -read
md4 = md_test_hard -stat
# find phase
md5 = [we supply parameters to find a subset of the files that were created in the
tests]
# score phase
bw = geo_mean( bw1 bw2 bw3 bw4)
md = geo_mean( md1 md2 md3 md4 bd5)
total = bw * md
Now we are moving on to precisely define what the parameters should look like for the
hard tests and to create a standard so that people can start running it on their systems.
By doing so, we will define the formal process so we can actually make this an official
benchmark. Please see the attached file in which we’ve started precisely defining these
parameters. Let’s start iterating please on this file to get these parameters correct.
Thanks,
John
_______________________________________________
IO-500 mailing list
IO-500(a)vi4io.org
https://www.vi4io.org/cgi-bin/mailman/listinfo/io-500
Cheers, Andreas
8:40 a.m.
On Jun 19, 2017, at 7:10 AM, Andreas Dilger
<adilger@dilger.ca<mailto:adilger@dilger.ca>> wrote:
On Jun 18, 2017, at 1:01 PM, Michael Kluge
<michael.kluge@tu-dresden.de<mailto:michael.kluge@tu-dresden.de>> wrote:
IOR has an option to allocate a certain amount of the hosts memory. I suggest that we set
this to 90-95 percent and the total amount of data written as twice the size of the main
memory? Otherwise, the 10+ PB main memory of SUMMIT would make the list useless ;)
If I read everything correctly the current run rules define an execution time of 5 minutes
and just count the numbers of bytes/iops/files touched during this time. I agree that most
of the time our users do I/O in bursts. Is the benchmark basically only about “who can
write the most data with one file per process in 5 mins”? Why 5 minutes and not “how long
does it take to dump 80% of the main memory to some redundant permanent storage” (with
fsync())?
The reason that a fixed time of 5 minutes was chosen for the write time is that this is
typically the maximum time to dump a full-system checkpoint every hour to get 90% compute
efficiency. If the limit is based on a particular data size then as you say the writes
might fit entirely into RAM and the storage isn't exercised at all. Conversely, for
checkpoints the size is rarely larger than the total RAM size.
Michael, I like your 90% memory idea. Like the 5 minute rule, it keeps the benchmark
from degrading over time. For example, if we said “how fast to do 1 PB,” then in 10
years, the test will be too small.
However, my concern about 90% of memory is that machines that have very small amounts of
memory will be able to fit all of their memory into server-side caches which might not
respect a sync command.
Do we want to define some rules about how safe the data has to be? Should it be OK if this
data ends up in a single burst buffer and there is no copy somewhere? I would recommend
that the results are only valid if data survives one failure of one of the storage devices
used. For example: For the mdtest-workload I could imagine a file system that has
directory locking turned off and is using an SSD/NVRAM backend and thus would just behave
like the “IOR hard” workload.
The goal of the benchmark is that there is a separate measurement for each layer of the
storage system. That would give one result for a flash/burst buffer tier, a separate
result for the disk-based storage.
Another point is that I am more a fan of application driven benchmarks. The numbers above
do not tell me anything about my applications, so why should I actually run the benchmark?
Just to to be “on the list”?
Applications are going to be different, even among HPC sites. The goal of the benchmark
is to try and determine the outer limits of the performance space of the storage. How
does it handle large aligned reads/writes, how does it handle unaligned small IOPS? How
fast are the primitive metadata operations and small files? With this raw information, it
should (in theory) be possible to derive the IO behaviour of actual applications.
Application driven benchmarks (something like SPEC CPU, but SPEC I/O), that scale with the
machine (and with the machines main memory) could actually become a standard that also the
industry could use to advertise their systems.
This benchmark is also intended to scale with the system size and performance, rather than
being a fixed size. At the same time, they are intended to be run within a reasonable
time period rather than taking many hours to run.
In addition, if we as a site have I/O patterns that are close to one of the benchmarks, we
could put some weight on this benchmark and adjust our tenders and the industry partner
would know how to design the storage system with respect to our special requirements. Just
because they know the I/O pattern because it is a standard and they know how to deal with
it.
Since the benchmark itself is essentially capturing orthogonal performance parameters of
the storage system, it should be possible to weight the results of the different test
phases to get something approaching your desired performance characteristics.
One more thing that the current approach does not deal with at all is the fact that in
very near future applications will access permanent storage using interfaces that IOR does
not cover and store data by using mov() instructions in the CPU. Thus, if the list is
established using some combination of IOR+MDTEST+POSIX, I think it has no chance to
reflect the really fast I/O subsystems that are coming like http://pmem.io/
The benchmark is not necessarily tied to POSIX. With IOR it is possible to run different
backend IO interfaces (HDF5, MPI-IO, S3 in newer versions), and I believe that mdtest has
been updated to do the same. It should be possible to interface IOR/mdtest with
persistent memory storage systems like DAOS as well.
Yes, mdtest has been ported to replace all the ugly #ifdef with the same IOR backend.
Nathan Hjelm did this work and will be pushing this back to the main LANL IOR github at
which point all the old mdtest repo’s will be deprecated. We are proposing that our IO500
will use this LANL github.
In terms of POSIX or not, this is the reason behind the easy/hard benchmarks. Currently
we are dictating POSIX for mdtest hard and IOR hard and allowing the submitter to use
whatever backend they want (including adding a new one) for mdtest easy and IOR easy.
Should we find ourselves in a POSIX-free future, we’ll change the POSIX requirement for
the hard.
Thanks,
John
Cheers, Andreas
Von: IO-500 [mailto:io-500-bounces@vi4io.org] Im Auftrag von John Bent
Gesendet: Freitag, 16. Juni 2017 22:30
An: io-500@vi4io.org<mailto:io-500@vi4io.org>
Betreff: [IO-500] Detailed benchmark proposal
All,
Sorry for the long silence on the mailing list. However, we have made some substantial
progress recently as we prepare for our ISC BOF next week. For those of you at ISC,
please join us from 11 to 12 on Tuesday in Substanz 1&2.
The progress that we have made recently happened because a bunch of us were attending a
German workshop last month at Dagstuhl and had multiple discussions about the benchmark.
Here’s the highlights from what was discussed and the progress that we made at Dagstuhl:
• General agreement that the IOR-hard, IOR-easy, mdtest-hard, mdtest-easy approach is
appropriate.
• We should add a ‘find’ command as this is a popular and important workload.
• The multiple bandwidth measurements should be combined via geometric mean into one
bandwidth.
• The multiple IOPs measurements should also be combined via geometric mean into one
IOPs.
• The bandwidth and the IOPs should be multiplied to create one final score.
• The ranking uses that final score but the webpage can be sorted using other metrics.
• The webpage should allow filtering as well so, for example, people can look at only the
HDD results.
• We should separate the write/create phases from the read/stat phases to help ensure that
caching is avoided
• Nathan Hjelm volunteered to combine the mdtest and IOR benchmarks into one git repo and
has now done so. This removes the #ifdef mess from mdtest and now they both share the
nice modular IOR backend
So the top-level summary of the benchmark in pseudo-code has become:
# write/create phase
bw1 = ior_easy -write [user supplies their own parameters maximizing data writes that can
be done in 5 minutes]
md1 = md_test_easy -create [user supplies their own parameters maximizing file creates
that can be done in 5 minutes]
bw2 = ior_hard -write [we supply parameters: unaligned strided into single shared file]
md2 = md_test_hard -create [we supply parameters: creates of 3900 byte files into single
shared directory]
# read/stat phase
bw3 = ior_easy -read [cross-node read of everything that was written in bw1]
md3 = md_test_easy -stat [cross-node stat of everything that was created in md1]
bw4 = ior_hard -read
md4 = md_test_hard -stat
# find phase
md5 = [we supply parameters to find a subset of the files that were created in the
tests]
# score phase
bw = geo_mean( bw1 bw2 bw3 bw4)
md = geo_mean( md1 md2 md3 md4 bd5)
total = bw * md
Now we are moving on to precisely define what the parameters should look like for the hard
tests and to create a standard so that people can start running it on their systems. By
doing so, we will define the formal process so we can actually make this an official
benchmark. Please see the attached file in which we’ve started precisely defining these
parameters. Let’s start iterating please on this file to get these parameters correct.
Thanks,
John
_______________________________________________
IO-500 mailing list
IO-500@vi4io.org<mailto:IO-500@vi4io.org>
https://www.vi4io.org/cgi-bin/mailman/listinfo/io-500
Cheers, Andreas
_______________________________________________
IO-500 mailing list
IO-500@vi4io.org<mailto:IO-500@vi4io.org>
https://www.vi4io.org/cgi-bin/mailman/listinfo/io-500

2:10 a.m.
I still think we are missing the mark a little. As someone building infrastructure,
streaming reads and writes and completely random unaligned small block
doesn't really give me the information I want. We should also address the
configuration for error correction because issues like mirroring in the controllers or
stripe verification dramatically impacts performance and a history of abuse here.
If I were to grossly generalize, what we would see is a write dominated bi-modal
distribution of random aligned 1 meg io's mixed with a similar number of
4k io's and a smattering between the two. There are typically order 100's of
independent i/o streams that make identifying and managing/coalescing sequential
streams difficult and while we see some coalescing at the block layer, its an area ripe
for improvement and an i/o system that could do that would be most useful.
The proposed tests may not reward that.
Its also the case that I don't want to over-provision i/o, so we will come in well
below many sites, but even so, we have lots of unused streaming capability
and are mostly impacted from SW design issues either within lustre or the application,
some can be dealt with like a finding users aggressively stat'ing a
non-existant file in parallel, and some are more embedded like the geometry of a given
simulation not matching up with the underlying device structure as the
requests make their way through several layers of SW like the FORTRAN I/O library, HDF,
NetCDF, etc.
So I guess my concrete suggestion is that a mixed workload number is most useful, and that
number will be no where near the peak throughput or the completely
random and I don't think that can be a derived quantity (i.e. geo mean), it must be
measured directly.
bob
-------------------------------------------------------------------------
Robert B. Ciotti Chief Systems Architect Supercomputing
NASA Advanced Supercomputing (NAS) Division TEL (650) 604-4408
NASA Ames Research Center FAX (650) 604-4377
P.O. Box 1, Moffett Field, CA 94035-0001 Bob.Ciotti(a)NASA.gov
-------------------------------------------------------------------------
On 06/16/2017 01:30 PM, John Bent wrote:
All,
Sorry for the long silence on the mailing list. However, we have made some substantial
progress recently as we prepare for our ISC BOF next week. For those of you at ISC,
please join us from 11 to 12 on Tuesday <x-apple-data-detectors://0> in Substanz
1&2.
The progress that we have made recently happened because a bunch of us were attending a
German workshop last month at Dagstuhl and had multiple discussions about the benchmark.
Here’s the highlights from what was discussed and the progress that we made at Dagstuhl:
1. General agreement that the IOR-hard, IOR-easy, mdtest-hard, mdtest-easy approach is
appropriate.
2. We should add a ‘find’ command as this is a popular and important workload.
3. The multiple bandwidth measurements should be combined via geometric mean into one
bandwidth.
4. The multiple IOPs measurements should also be combined via geometric mean into one
IOPs.
5. The bandwidth and the IOPs should be multiplied to create one final score.
6. The ranking uses that final score but the webpage can be sorted using other metrics.
7. The webpage should allow filtering as well so, for example, people can look at only
the HDD results.
8. We should separate the write/create phases from the read/stat phases to help ensure
that caching is avoided
9. Nathan Hjelm volunteered to combine the mdtest and IOR benchmarks into one git repo
and has now done so. This removes the #ifdef mess from mdtest and now they both share the
nice modular IOR backend
So the top-level summary of the benchmark in pseudo-code has become:
# write/create phase
bw1 = ior_easy -write [user supplies their own parameters maximizing data writes that can
be done in 5 minutes]
md1 = md_test_easy -create [user supplies their own parameters maximizing file creates
that can be done in 5 minutes]
bw2 = ior_hard -write [we supply parameters: unaligned strided into single shared file]
md2 = md_test_hard -create [we supply parameters: creates of 3900 byte files into single
shared directory]
# read/stat phase
bw3 = ior_easy -read [cross-node read of everything that was written in bw1]
md3 = md_test_easy -stat [cross-node stat of everything that was created in md1]
bw4 = ior_hard -read
md4 = md_test_hard -stat
# find phase
md5 = [we supply parameters to find a subset of the files that were created in the
tests]
# score phase
bw = geo_mean( bw1 bw2 bw3 bw4)
md = geo_mean( md1 md2 md3 md4 bd5)
total = bw * md
Now we are moving on to precisely define what the parameters should look like for the
hard tests and to create a standard so that people can start running it on their systems.
By doing so, we will define the formal process so we can actually make this an official
benchmark. Please see the attached file in which we’ve started precisely defining these
parameters. Let’s start iterating please on this file to get these parameters correct.
Thanks,
John
_______________________________________________
IO-500 mailing list
IO-500(a)vi4io.org
https://www.vi4io.org/cgi-bin/mailman/listinfo/io-500
8:43 p.m.
Dear Bob,
when a result is posted the configuration should be posted it should
probably cover, e.g., RAID levels. It is a good idea to explitly
mention that these things are part of the system configuration for the
submission.
I presume many of us agree with the fact that the benchmarks won't
cover everything.
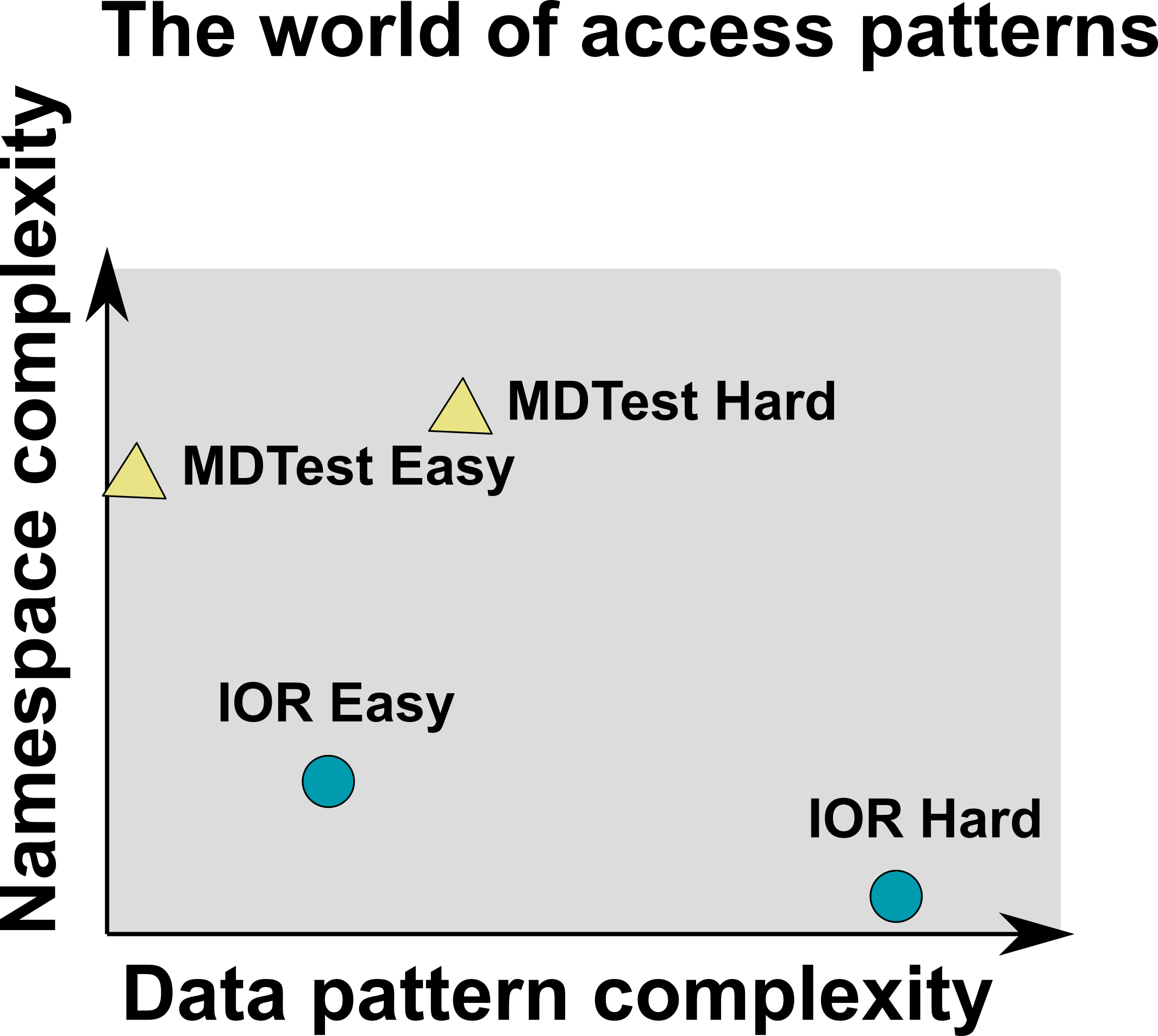
I added a simpliefied view I have from a single I/O pattern as figure
(complexity / hardness is considered to be similar).
Concurrent patterns lead to more complex behavior, e.g., adding a
third dimension, while the ones we currently cover are a 2D plane in
such a 3D space.
The problem with that is they are even more difficult to understand
and performance is more difficult to assess.
IMHO we are in the phase to define initial benchmarks that aim to,
e.g., cover some subset of the possible 2d space.
I believe the defined benchmarks are useful and, yes, they are
absolutely not the full story.
When we procure we do sth. similar anyway to understand the system
basis behavior.
But, having these numbers for many systems will be a huge progress
compared to not having any number at disposal at all.
We may potentially add more useful benchmarks that show congestion
behavior in a while.
The suggestion you made is nice, a single benchmark that does both patterns.
If it would be two benchmarks, the system may stall the small I/Os and
first do the large and vice versa, so a single benchmark that does
both (Write 1M, Write 47K, Write 1M) would probably be OK to simulate
such behavior.
Hopefully very few applications do that, though, and if they do we
would try to adjust them.
We probably should evaluate any new benchmark and show its benefit to
reveal (interesting) system behavior to the community.
Ultimately we may add further I/O dwarfs to "a benchmark" suite that
will be submitted that you may optionally rank according to your wish.
This could be an IO-500 "extended mode" that takes longer to run and
adds these additional values.
However, maybe it is useful for us move a bit slower and potentially
agree on "easy" to define and agree upon those patterns first and show
their benefit.
The question is: can we change something slightly for having 4
benchmarks, to make the benchmarks even more useful without discussing
adding further access patterns?
Regards,
Julian
2017-06-20 4:10 GMT+02:00 Bob Ciotti <Bob.Ciotti(a)nasa.gov>:
I still think we are missing the mark a little. As someone building
infrastructure, streaming reads and writes and completely random unaligned
small block
doesn't really give me the information I want. We should also address the
configuration for error correction because issues like mirroring in the
controllers or
stripe verification dramatically impacts performance and a history of abuse
here.
If I were to grossly generalize, what we would see is a write dominated
bi-modal distribution of random aligned 1 meg io's mixed with a similar
number of
4k io's and a smattering between the two. There are typically order 100's of
independent i/o streams that make identifying and managing/coalescing
sequential
streams difficult and while we see some coalescing at the block layer, its
an area ripe for improvement and an i/o system that could do that would be
most useful.
The proposed tests may not reward that.
Its also the case that I don't want to over-provision i/o, so we will come
in well below many sites, but even so, we have lots of unused streaming
capability
and are mostly impacted from SW design issues either within lustre or the
application, some can be dealt with like a finding users aggressively
stat'ing a
non-existant file in parallel, and some are more embedded like the geometry
of a given simulation not matching up with the underlying device structure
as the
requests make their way through several layers of SW like the FORTRAN I/O
library, HDF, NetCDF, etc.
So I guess my concrete suggestion is that a mixed workload number is most
useful, and that number will be no where near the peak throughput or the
completely
random and I don't think that can be a derived quantity (i.e. geo mean), it
must be measured directly.
bob
-------------------------------------------------------------------------
Robert B. Ciotti Chief Systems Architect Supercomputing
NASA Advanced Supercomputing (NAS) Division TEL (650) 604-4408
NASA Ames Research Center FAX (650) 604-4377
P.O. Box 1, Moffett Field, CA 94035-0001 Bob.Ciotti(a)NASA.gov
-------------------------------------------------------------------------
On 06/16/2017 01:30 PM, John Bent wrote:
>
> All,
>
> Sorry for the long silence on the mailing list. However, we have made some
> substantial progress recently as we prepare for our ISC BOF next week. For
> those of you at ISC, please join us from 11 to 12 on Tuesday
> <x-apple-data-detectors://0> in Substanz 1&2.
>
> The progress that we have made recently happened because a bunch of us
> were attending a German workshop last month at Dagstuhl and had multiple
> discussions about the benchmark.
>
> Here’s the highlights from what was discussed and the progress that we
> made at Dagstuhl:
>
> 1. General agreement that the IOR-hard, IOR-easy, mdtest-hard,
> mdtest-easy approach is appropriate.
> 2. We should add a ‘find’ command as this is a popular and important
> workload.
> 3. The multiple bandwidth measurements should be combined via geometric
> mean into one bandwidth.
> 4. The multiple IOPs measurements should also be combined via geometric
> mean into one IOPs.
> 5. The bandwidth and the IOPs should be multiplied to create one final
> score.
> 6. The ranking uses that final score but the webpage can be sorted using
> other metrics.
> 7. The webpage should allow filtering as well so, for example, people can
> look at only the HDD results.
> 8. We should separate the write/create phases from the read/stat phases
> to help ensure that caching is avoided
> 9. Nathan Hjelm volunteered to combine the mdtest and IOR benchmarks into
> one git repo and has now done so. This removes the #ifdef mess from mdtest
> and now they both share the nice modular IOR backend
>
>
> So the top-level summary of the benchmark in pseudo-code has become:
>
> # write/create phase
> bw1 = ior_easy -write [user supplies their own parameters maximizing data
> writes that can be done in 5 minutes]
> md1 = md_test_easy -create [user supplies their own parameters maximizing
> file creates that can be done in 5 minutes]
> bw2 = ior_hard -write [we supply parameters: unaligned strided into single
> shared file]
> md2 = md_test_hard -create [we supply parameters: creates of 3900 byte
> files into single shared directory]
>
> # read/stat phase
> bw3 = ior_easy -read [cross-node read of everything that was written in
> bw1]
> md3 = md_test_easy -stat [cross-node stat of everything that was created
> in md1]
> bw4 = ior_hard -read
> md4 = md_test_hard -stat
>
> # find phase
> md5 = [we supply parameters to find a subset of the files that were
> created in the tests]
>
> # score phase
> bw = geo_mean( bw1 bw2 bw3 bw4)
> md = geo_mean( md1 md2 md3 md4 bd5)
> total = bw * md
>
> Now we are moving on to precisely define what the parameters should look
> like for the hard tests and to create a standard so that people can start
> running it on their systems. By doing so, we will define the formal process
> so we can actually make this an official benchmark. Please see the attached
> file in which we’ve started precisely defining these parameters. Let’s
> start iterating please on this file to get these parameters correct.
>
> Thanks,
>
> John
>
>
> _______________________________________________
> IO-500 mailing list
> IO-500(a)vi4io.org
> https://www.vi4io.org/cgi-bin/mailman/listinfo/io-500
>
_______________________________________________
IO-500 mailing list
IO-500(a)vi4io.org
https://www.vi4io.org/cgi-bin/mailman/listinfo/io-500
--
http://wr.informatik.uni-hamburg.de/people/julian_kunkel
{kind=link}
11:31 p.m.
On Jun 19, 2017, at 8:10 PM, Bob Ciotti <Bob.Ciotti(a)nasa.gov> wrote:
I still think we are missing the mark a little. As someone building infrastructure,
streaming reads and writes and completely random unaligned small block
doesn't really give me the information I want. We should also address the
configuration for error correction because issues like mirroring in the controllers or
stripe verification dramatically impacts performance and a history of abuse here.
I think this exposes an interesting question for the benchmark - what data to record for
each run, and what is available on the website?
There are a number of datapoints that can be easily recorded from the client when the test
is run and should be automatically collected and reported by the test script (filesystem
type, filesystem name/mountpoint, filesystem version, total/free filesystem space/inodes,
client OS version, client CPU/RAM/network, client count, ...). There are a large number
of other parameters that may not be immediately visible, such as tuning parameters, etc.
but that could be extracted programatically.
There are also many parameters that are not visible to the client regarding how the
servers are configured, and this would need to be manually entered by the tester.
Possibly we could have a script that collects similar data on the client and server, that
knows about the filesystem type (Lustre, GPFS, etc.) that can extract the interesting data
about the underlying storage, tunables, OS, software, etc. but I suspect this will need to
be an incremental effort or it will never be done. One option is to dump a large amount
of data (e.g. lspci, lsscsi, lscpu, Lustre config logs, etc.) into a file that accompanies
the test result, and this can be available as a "blob" for future reference
and/or extraction as our data collection becomes more advanced. That "blob"
would grow as more information is considered relevant
Cheers, Andreas
10:55 p.m.
On Jun 21, 2017, at 1:31 AM, Andreas Dilger <adilger(a)dilger.ca>
wrote:
On Jun 19, 2017, at 8:10 PM, Bob Ciotti <Bob.Ciotti(a)nasa.gov> wrote:
>
> I still think we are missing the mark a little. As someone building infrastructure,
streaming reads and writes and completely random unaligned small block
> doesn't really give me the information I want. We should also address the
configuration for error correction because issues like mirroring in the controllers or
stripe verification dramatically impacts performance and a history of abuse here.
Thanks Bob. We hope that we will be able to capture enough info to address this
concern. Julian has been very active in building the database and webpage integration so
you should be able to do things like filter the results for only systems that used
spinning disks and at least RAID-6 durability for example.
I think this exposes an interesting question for the benchmark - what
data to record for each run, and what is available on the website?
There are a number of datapoints that can be easily recorded from the client when the
test is run and should be automatically collected and reported by the test script
(filesystem type, filesystem name/mountpoint, filesystem version, total/free filesystem
space/inodes, client OS version, client CPU/RAM/network, client count, ...). There are a
large number of other parameters that may not be immediately visible, such as tuning
parameters, etc. but that could be extracted programatically.
There are also many parameters that are not visible to the client regarding how the
servers are configured, and this would need to be manually entered by the tester.
Possibly we could have a script that collects similar data on the client and server, that
knows about the filesystem type (Lustre, GPFS, etc.) that can extract the interesting data
about the underlying storage, tunables, OS, software, etc. but I suspect this will need to
be an incremental effort or it will never be done. One option is to dump a large amount
of data (e.g. lspci, lsscsi, lscpu, Lustre config logs, etc.) into a file that accompanies
the test result, and this can be available as a "blob" for future reference
and/or extraction as our data collection becomes more advanced. That "blob"
would grow as more information is considered relevant
Thank you Andreas. I know that we are all very interested in doing just this and
you are right that it will be hard to capture everything that anyone might later realize
is relevant. As a guiding principle we are requiring that submissions provide enough
information such that they are reproducible by others. So all tuning that was done should
be included. How much is included in a blob and how much goes into the DB schema is yet
to be determined. When I did PanFS testing at LANL, we put everything into a database and
had a bash script that ran after the benchmark that tried to collect tons of environmental
info. Maybe I can dig that up as well as the database schema.
Thanks,
John
Cheers, Andreas
<signature.asc>_______________________________________________
IO-500 mailing list
IO-500(a)vi4io.org
https://www.vi4io.org/cgi-bin/mailman/listinfo/io-500
2507
days inactive
2514
days old
9 comments
5 participants
participants (5)
-
 Andreas Dilger
Andreas Dilger -
 Bob Ciotti
Bob Ciotti -
 John Bent
John Bent -
 Julian Kunkel
Julian Kunkel -
 Michael Kluge
Michael Kluge